400-001-9776
400-001-9776
近日,國家互聯網信息辦公室發布的《數據安全管理辦法(征求意見稿)》,對各方關注的數據安全問題的管理進行了直接回應。可見國家對數據安全的重視。
5G、云計算、物聯網、人工智能、工業互聯網和區塊鏈等新興技術飛速變革,以數字化、網絡化為核心的信息變革深刻改變著世界,這個時代已經越來越離不開數據。數據量越大,安全保障的責任就越大。數據安全已經事關經濟社會大局。
做好數據梳理是數據安全治理的第一步,也是關鍵的一步。通過數據梳理可以識別關鍵業務數據及其面臨的風險,完善組織數據保護政策,有效落實數據安全管理規定,降低業務運營風險,建立動態可持續的數據安全運維管理保障體系。
如何做好數據梳理呢?
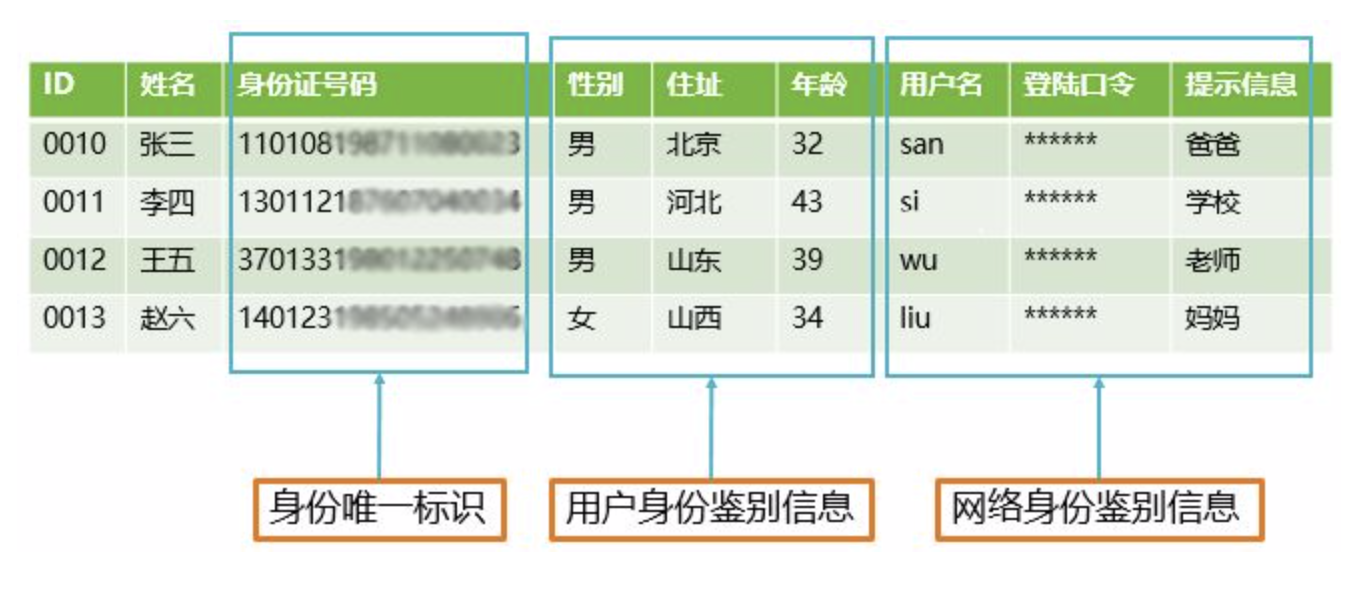
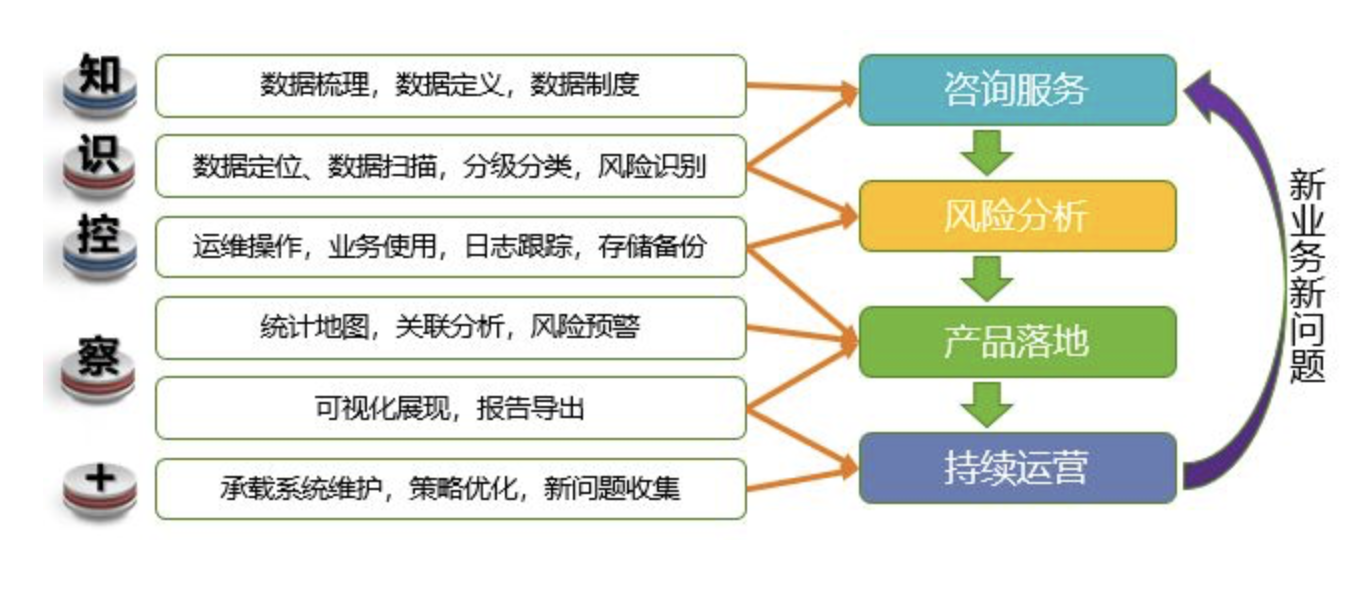
《網絡安全法》《等級保護2.0》將敏感數據分為“個人隱私數據”和“企業敏感數據”兩大類,而落實到應用中,我們會發現還有一種衍生數據是不好界定的,比如消費信息、行為信息等等。現在只有運營商行業出臺的數據安全標準或規范相對較完善,我們參考了《中國移動大數據安全管控分類分級實施指南》可以看到更細致的數據分類,及“A類:用戶身份相關數據”、“B類:用戶服務內容數據”、“C類:用戶服務衍生數據”、“D類:企業運營管理數據”共四類,這樣分類更加明確和具體。 通過上述對敏感數據的定義與歸類,可以從全局上把控自身企業中包含的敏感數據的內容,再根據自身的業務情況,可以快速的定義敏感數據,并確定敏感數據的類型和級別,為今后數據管理提供有利的數據支撐。 數據分為結構化數據、半結構化數據、非結構化數據。結構化的數據是指可以使用關系型數據庫表示和存儲,表現為二維形式的數據;半結構化數據是結構化數據的一種形式,它并不符合關系型數據庫或其他數據表的形式關聯起來的數據模型結構,但它含相關標記,用來分隔語義元素以及對記錄和字段進行分層;非結構化數據就是沒有固定結構的數據。在大數據環境中,這三類數據都會存在,并且被合理的存儲和使用。 從數據存儲和使用的角度,我們會發現數據有兩種形態,分別為靜態數據和動態數據,下面,我們就以大數據環境Hadoop為例來看看數據都在哪里。 從上圖可以看出,靜態數據滯留在數據存儲層,而動態數據則出現在數據分析層、數據共享層、數據應用層。在數據存儲層利用主動掃描的技術可以快速發現和梳理靜態數據,在數據分析層、數據共享層、數據應用層,我們可以利用監聽的方式獲取動態數據以及數據的流轉與轉換情況,監聽方式包括:鏈路旁路鏡像和插件Agent方式。 綜上所述,企業敏感數據梳理,需要根據自身業務特點進行數據的挖掘分析,再利用現代化的工具快速的實現企業敏感數據的發現與分類分級,并根據梳理的結果實現數據風險的分析與展現。 綠盟數據安全解決方案為數據安全設計全面可信的防御體系,提出“知”、“識”、“控”、“察”的數據安全治理方法論,包括數據梳理、運維數據監管、業務數據監管、辦公數據監管、數據可視化的完整解決方案,有效保護數據在全生命周期過程中的安全,達到合法采集、合理利用、靜態可知、動態可控的防護目標。第一步:定義敏感數據
第二步:敏感數據追蹤

第三步:敏感數據挖掘